Il file robots.txt è uno degli elementi più fraintesi della SEO tecnica. Spesso ignorato nella radice del sito, viene notato solo quando scatta il panico: una pagina importante non compare su Google, oppure Google Search Console inizia a segnalare avvisi incomprensibili.
La verità? Copiare e incollare regole trovate a caso sul web è il modo più veloce per far sparire il tuo sito dai motori di ricerca.
In questa guida completa al file robots.txt vedremo esattamente cos’è, come funziona, quali sono i falsi miti che devi smettere di credere e ti forniremo esempi pratici da usare subito.
Che cos’è il file robots.txt?
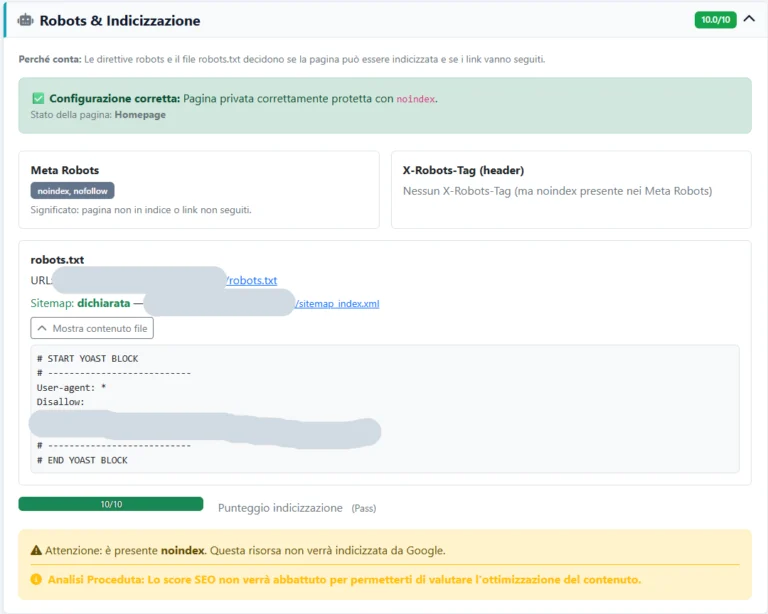
Il file robots.txt è un semplice file di testo (.txt) posizionato nella cartella principale (root) di un sito web. Il suo scopo è comunicare con i crawler dei motori di ricerca (come Googlebot), indicando loro quali pagine o sezioni del sito possono o non possono scansionare.
Puoi immaginarlo come il buttafuori all’ingresso del tuo sito web. Quando Google arriva, la primissima cosa che fa è cercare questo file, solitamente all’indirizzo:
https://www.tuosito.it/robots.txt (Tuo sito, inserisci il sito da controllare)
Nota fondamentale sulla posizione: Se il file viene caricato in una sottocartella (es. tuosito.it/blog/robots.txt), i motori di ricerca lo ignoreranno completamente. Deve vivere esclusivamente nella root principale del dominio o del sottodominio a cui fa riferimento.
A cosa serve davvero? (Scansione vs. Indicizzazione)
Il compito del robots.txt è gestire il budget di scansione (Crawl Budget) ed evitare che i motori di ricerca perdano tempo su risorse inutili.
Serve a dire a Google: “Ehi, puoi guardare tutto il catalogo, ma per favore non entrare nella cartella dove tengo le fatture in PDF o nelle pagine di login dei miei dipendenti”.
Ecco un esempio base:
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Sitemap: https://www.tuosito.it/sitemap_index.xml
- User-agent: *** si rivolge a tutti i bot della rete.
- Disallow: indica la cartella vietata (in questo caso, il pannello di amministrazione).
- Allow: crea un’eccezione, permettendo l’accesso a un file specifico dentro la cartella bloccata.
- Sitemap: indica al bot dove trovare la mappa del sito.
I 3 grandi miti sul robots.txt (Cosa NON fa)
Per evitare disastri SEO, è vitale capire i limiti di questo strumento.
1. “Il robots.txt nasconde le pagine da Google” (FALSO)
Impedire la scansione di una pagina non significa che questa non apparirà su Google. Se altri siti linkano quella pagina, Google saprà che esiste e potrebbe mostrarla nei risultati di ricerca, mostrandola senza la meta description (con la dicitura “Nessuna informazione disponibile per questa pagina”).
2. “Posso usarlo per proteggere dati sensibili” (FALSO)
Il file robots.txt è pubblico. Chiunque può digitare il tuo indirizzo seguito da /robots.txt e leggere l’elenco esatto delle cartelle che stai cercando di nascondere. Se hai documenti riservati, non usare il robots.txt: proteggili con una password lato server.
3. “È un’alternativa al tag Noindex” (FALSO)
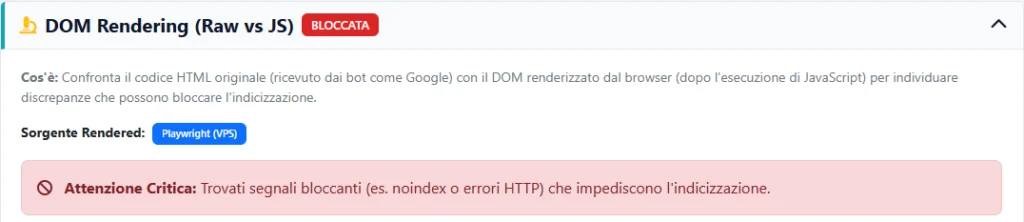
Questo è l’errore più grave. Se inserisci una pagina nel robots.txt tramite Disallow, impedisci a Google di entrare in quella pagina. Di conseguenza, se all’interno della pagina hai inserito un tag “Noindex” per chiederne la rimozione da Google, il bot non potrà mai leggerlo.
Differenza tra Robots.txt, Noindex e Canonical
Per chiarire definitivamente la confusione tecnica, ecco quando usare cosa:
| Strumento | Funzione principale | Quando si usa? |
| Robots.txt | Blocca la scansione | Per tenere i bot fuori da cartelle di sistema, filtri complessi di e-commerce o script non necessari. |
| Tag Noindex | Blocca l’indicizzazione | Quando vuoi che una pagina (es. una “Thank You Page” o una landing page per una promo) sparisca dai risultati di Google. |
| Tag Canonical | Gestisce le duplicazioni | Quando hai due contenuti quasi identici e vuoi indicare a Google qual è quello “ufficiale” da posizionare. |
Esempi pratici di robots.txt
A seconda del tuo sito, le esigenze cambiano. Ecco alcuni scenari concreti.
1. Il sito aziendale o blog WordPress (Configurazione Consigliata)
Non complicare le cose se non è necessario. Un sito WordPress moderno ha bisogno che Google acceda a JavaScript e CSS per capire come è fatta la pagina.
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Sitemap: https://www.tuosito.it/sitemap_index.xml
2. Bloccare le ricerche interne infinite
Se il tuo sito ha una barra di ricerca interna che genera migliaia di URL inutili (es. tuosito.it/?s=scarpe-rosse), è bene bloccarle per non sprecare Crawl Budget.
User-agent: *
Disallow: /?s=
Disallow: /search/
Sitemap: https://www.tuosito.it/sitemap_index.xml
3. Evitare che le immagini finiscano su Google Images
Se hai immagini proprietarie che non vuoi far indicizzare nel motore di ricerca per immagini (pur mantenendole visibili sul sito):
User-agent: Googlebot-Image
Disallow: /
4. L’errore fatale: il sito invisibile
Questa singola riga di codice, spesso dimenticata dalle agenzie dopo aver messo online un nuovo sito (passaggio da ambiente di staging a produzione), fa letteralmente sparire il sito da Google.
User-agent: *
Disallow: /
Se vedi quel / da solo dopo Disallow, rimuovilo immediatamente!
Come controllare se il tuo sito è a posto
- Ispezione manuale: Digita nel browser
tuosito.it/robots.txt. Assicurati che non ci sia il temutoDisallow: /. - Usa Google Search Console: Nella sezione “Pagine”, se vedi errori come “Indicizzata, ma bloccata da robots.txt“, significa che stai inviando segnali contrastanti a Google (stai bloccando la scansione di una pagina che Google ritiene interessante).
- Analisi tecnica completa: Dopo aver sistemato le direttive base, è fondamentale avere una panoramica della salute del tuo sito. Puoi affidarti a strumenti mirati come la nostra web app di analisi SEO completamente gratuita SEO Radar Italia, che è un, appunto, tool gratuito e strutturato in un’unica pagina, l’ideale per fare un’analisi SEO on-page veloce e capire se ci sono altri blocchi tecnici in corso.
Checklist Rapida
Prima di chiudere il file e salvarlo sul server, fatti queste domande:
- Il file si trova nella root principale del dominio?
- Blocca erroneamente risorse visive (CSS o JavaScript)?
- Contiene il link corretto alla Sitemap XML?
- Ho usato il
Disallowal posto delNoindexper cercare di deindicizzare una pagina? - L’area amministrativa e le cartelle di test sono bloccate correttamente?
In conclusione robot.txt non fa magie.
Il file robots.txt non è una bacchetta magica per la SEO: non ti farà scalare le classifiche di Google. Tuttavia, se configurato male, ha il potere di distruggere il tuo traffico organico in poche ore.
La regola d’oro è la semplicità: blocca solo ciò che è strettamente necessario. Permetti ai motori di ricerca di scansionare il tuo sito liberamente e usa i tag corretti (come il noindex) quando vuoi rimuovere dei contenuti.